ADsP 3과목 데이터 분석 : 표본 추출 방법, 자료의 척도, 기초 통계량, 첨도와 왜도
전수조사와 표본조사
- 어떤 결과를 알고 싶을 때 일부만 조사할지 전체를 다 조사할지
1) 전수조사 : 표본 전체를 조사, 시간과 비용이 많이 소모됨
2) 표본조사 : 표본 中 일부만 조사하여 모집단을 분석함 (ex. 출구조사)
표본 추출 방법
1) 랜덤 추출법 : 표본 중 무작위로 추출함
2) 계통 추출법 : 표본마다 번호를 부여하여 일정한 간격으로 추출함
1 → 3 → 5 → 7 혹은 2 → 4 → 6 → 8 순서로 추출
3) 집락 추출법 : 표본들을 군집으로 나눠서 군집 중에 랜덤으로 추출함
아파트 동마다 묶어서 그중에 한 동만 추출하는 식
군집 간 동질적 특징 가짐, 군집 내 이질적 특징 가짐
4) 층화 추출법 : 군집 간 이질적 특징, 군집 내 동질적 특징
1학년끼리 군집 / 2학년끼리 군집 / 3학년끼리 군집
비율을 같게 추출 시 : 비례 층화 추출법
ㄴ 학년별 인원수가 100명 200명 300명이면 1:2:3 비율
5) 복원 추출, 비복원 추출
-. 복원 추출 : 추출된 데이터를 다시 포함시켜 표본을 추출함
-. 비복원 추출 : 추출된 데이터는 제외시키고 표본 추출
자료의 척도 구분
1) 질적 척도
- 명목척도 : 어느 집단에 속하는지를 나타내는 자료 (회사, 성별)
- 순서척도(서열척도) : 서열관계가 존재하는 자료 (직급, 순위)
2) 양적 척도
- 등간척도 : 덧셈과 뺄셈만 가능, 구간 사이의 간격이 의미가 있음 (온도 等)
- 비율척도 : 기준 0이 존재, 사칙연산이 가능 (무게, 나이 等)
기초 통계량
1) 평균(mean) : 전체 합 / 개수
2) 중앙값(median) : 데이터를 크기순으로 나열했을 때 가운데 값
3) 최빈값(mode) : 가장 빈번하게 나타나는 값
4) 분산(variance) : 데이터들이 퍼져있는 정도를 나타냄
표준편차(Standard deviation) : 분산의 제곱 근
5) 공분산(cov) : 두 확률변수의 상관정도
- 공분산이 0 일 때 : 상관이 전혀 없음
- 공분산 > 0 일 때 : 양의 상관관계
- 공분산 < 0 일 때 : 음의 상관관계
- 공분산은 ± ∞ 까지 갈 수 있음
- 최소, 최댓값이 없어 강약 판단이 어려움
- 공분산은 -1 ~ 1의 값을 갖는 게 아님
6) 상관계수
-. 공분산으로 강약 판단이 불가하기 때문에 상관계수로 표현
-. 상관정도를 -1 ~ +1 값으로 표현
-. 상관계수 = -1 : 반비례 관계
-. 상관계수 = 1 : 정비례 관계
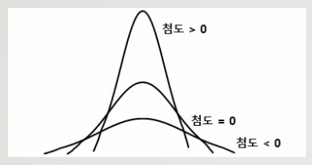
첨도와 왜도
1) 첨도(kurtosis) : 자료의 분포가 얼마나 뾰족한지 나타내는 척
-. 첨도 = 0 or 3 : 정규분포 형태를 띰
-. 첨도값이 클수록 뾰족한 모양
-. 값이 작을수록 평평한 모양
2) 왜도(skewness) : 데이터 분포의 좌우 비대칭 정도를 나타내는 척도
-. 왜도 = 0 일 때 : 평균값 = 중앙값 = 최빈값 일치함, 좌/우 대칭상태
-. 왜도 > 0 일 때 : 최빈값 < 중앙값 < 평균값
-. 왜도 < 0 일 때 : 최빈값 > 중앙값 > 평균

//
- //
1) //